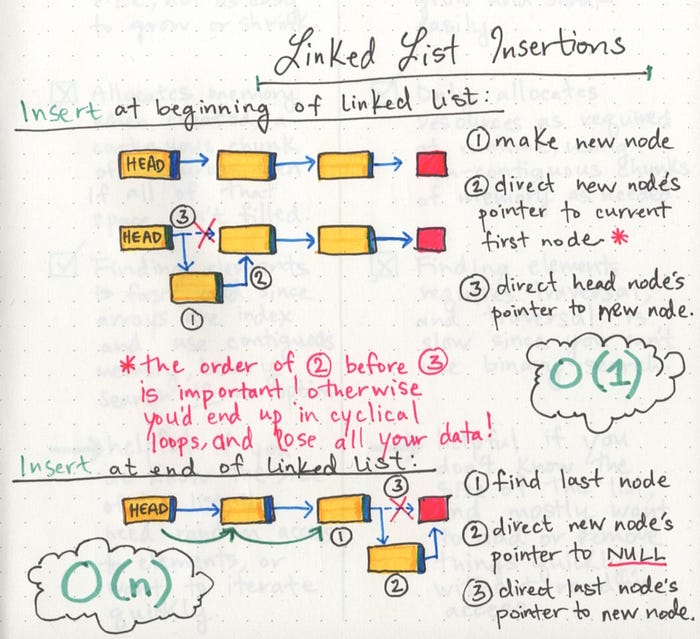
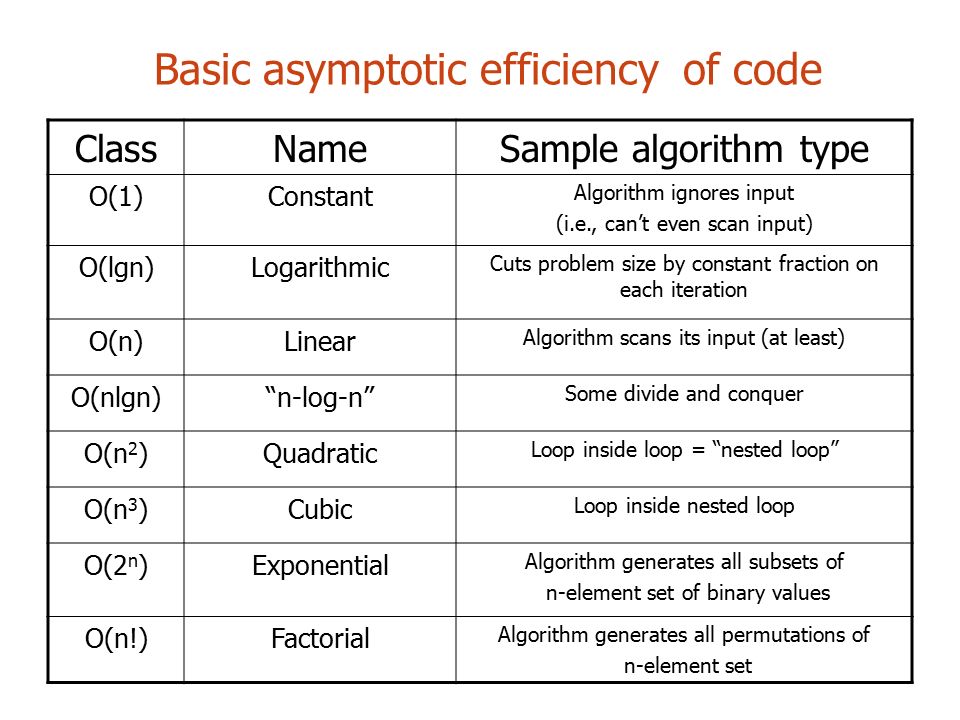
Big O: Analysis of Algorithm Efficiency
Big O(oh) notation is used to describe the efficiency of an algorithm or function. This efficiency is evaluated based on 2 factors:
-
Running Time (also known as time efficiency / complexity) The amount of time a function needs to complete.
-
Memory Space (also known as space efficiency / complexity) The amount of memory resources a function uses to store data and instructions.
Big O’s role in algorithm efficiency is to describe the Worst Case of efficiency an algorithm can have in performing it’s job. It specifically looks at the factors mentioned above, which we often refer to as Space and Time. In order to analyze these limiting factors, we should consider 4 Key Areas for analysis:
- Input Size
- Units of Measurement
- Orders of Growth
- Best Case, Worst Case, and Average Case
Orders of Growth
We can describe overall efficiency by using the input size n and measuring the overall Units of Space and Time required for the given input size n. As the value of n grows, the Order of Growth represents the increase in Running Time or Memory Space.
- Big O: The worst case analysis of algorithm efficiency.
- Running Time: The amount of time required for an algorithm to complete.
- Memory Space: The amount of memory resources required for an algorithm to complete.
- Input Size: Represented by the variable n, the total size of values used as parameters in an algorithm.
- Big Omega: The best case analysis of algorithm efficiency.
- Big Theta: The typical or random case used for analysis of algorithm efficiency.
Linked Lists
A Linked List is a sequence of Nodes that are connected/linked to each other. The most defining feature of a Linked List is that each Node references the next Node in the link. There are two types of Linked List - Singly and Doubly. We will be implementing a Singly Linked List in this implementation.
- Linked List - A data structure that contains nodes that links/points to the next node in the list.
- Singly - Singly refers to the number of references the node has. A Singly linked list means that there is only one reference, and the reference points to the Next node in a linked list.
- Doubly - Doubly refers to there being two (double) references within the node. A Doubly linked list means that there is a reference to both the Next and Previous node.
- Node - Nodes are the individual items/links that live in a linked list. Each node contains the data for each link.
- Next - Each node contains a property called Next. This property contains the reference to the next node.
- Head - The Head is a reference of type Node to the first node in a linked list.
- Current - The Current is a reference of type Node to the node that is currently being looked at. When traversing, you create a new Current variable at the Head to guarantee you are starting from the beginning of the linked list.
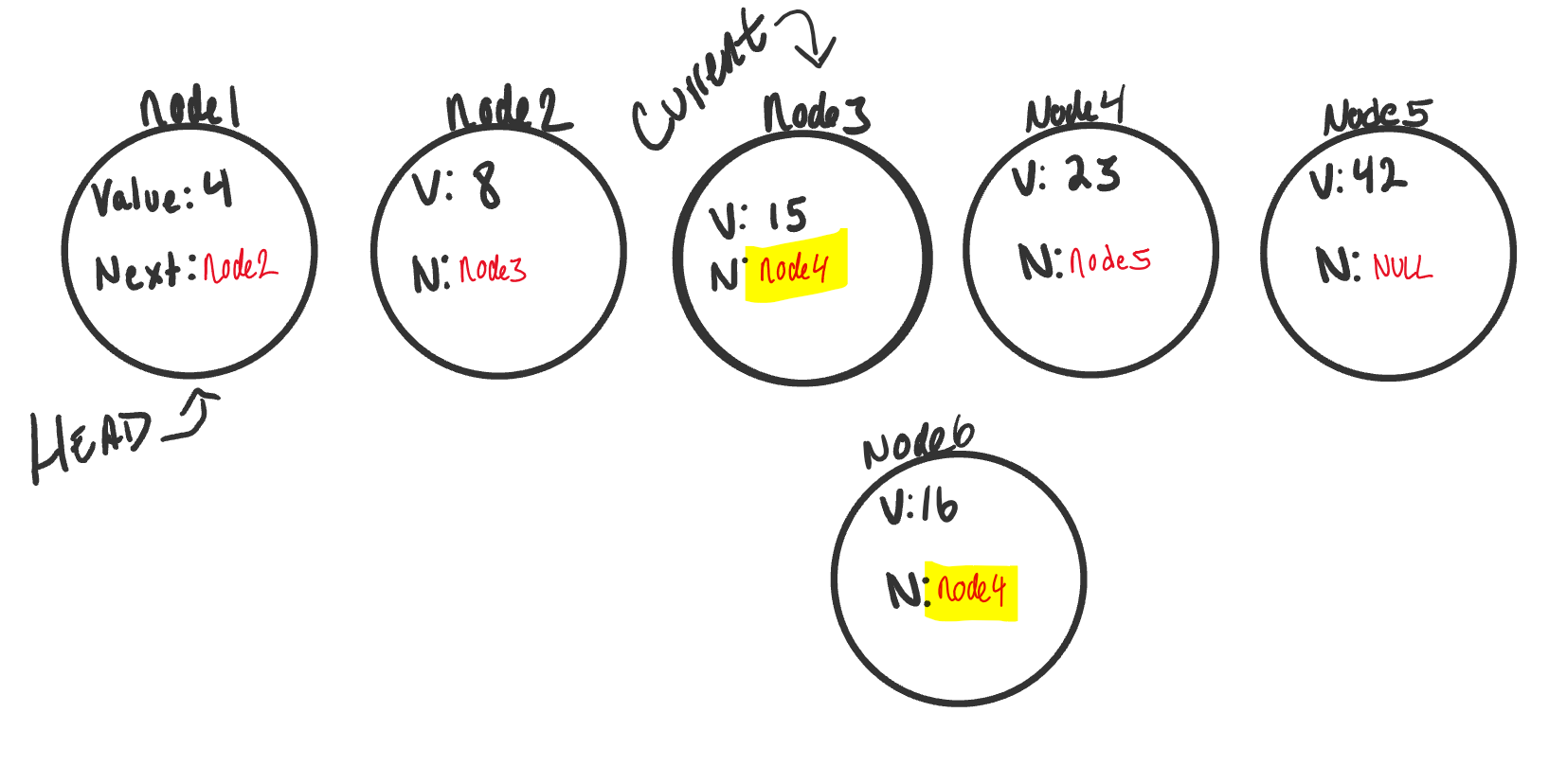
- The Linked List image above is in the following state: 1.Current is pointing to node3. 2.node3.Next property is equal to node4. 3.Since this is the node we want to insert before, we can now set our node6.Next property also to node4. We do this at the time the node is found to prevent setting node6.Next to a node that may not exist. 4.Uh-Oh, now both node3 and node6 are pointing to the same next node. node6 is not quite fully apart of the linked list. 5.Next, we have to adjust node3.Next to point to the newly created node, node6. Since we still have Current pointing to node3 this will be a straightforward transaction. We just simply tell Current (because it is pointing to the same memory location as node3) to change it’s Next to point to the new node (node6).
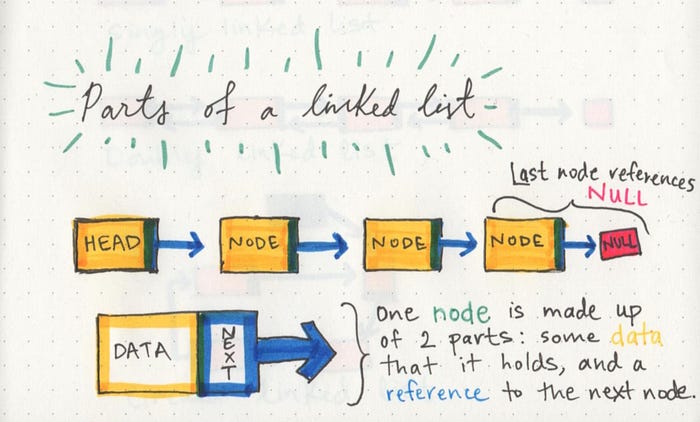
What’s a Linked List, Anyway?
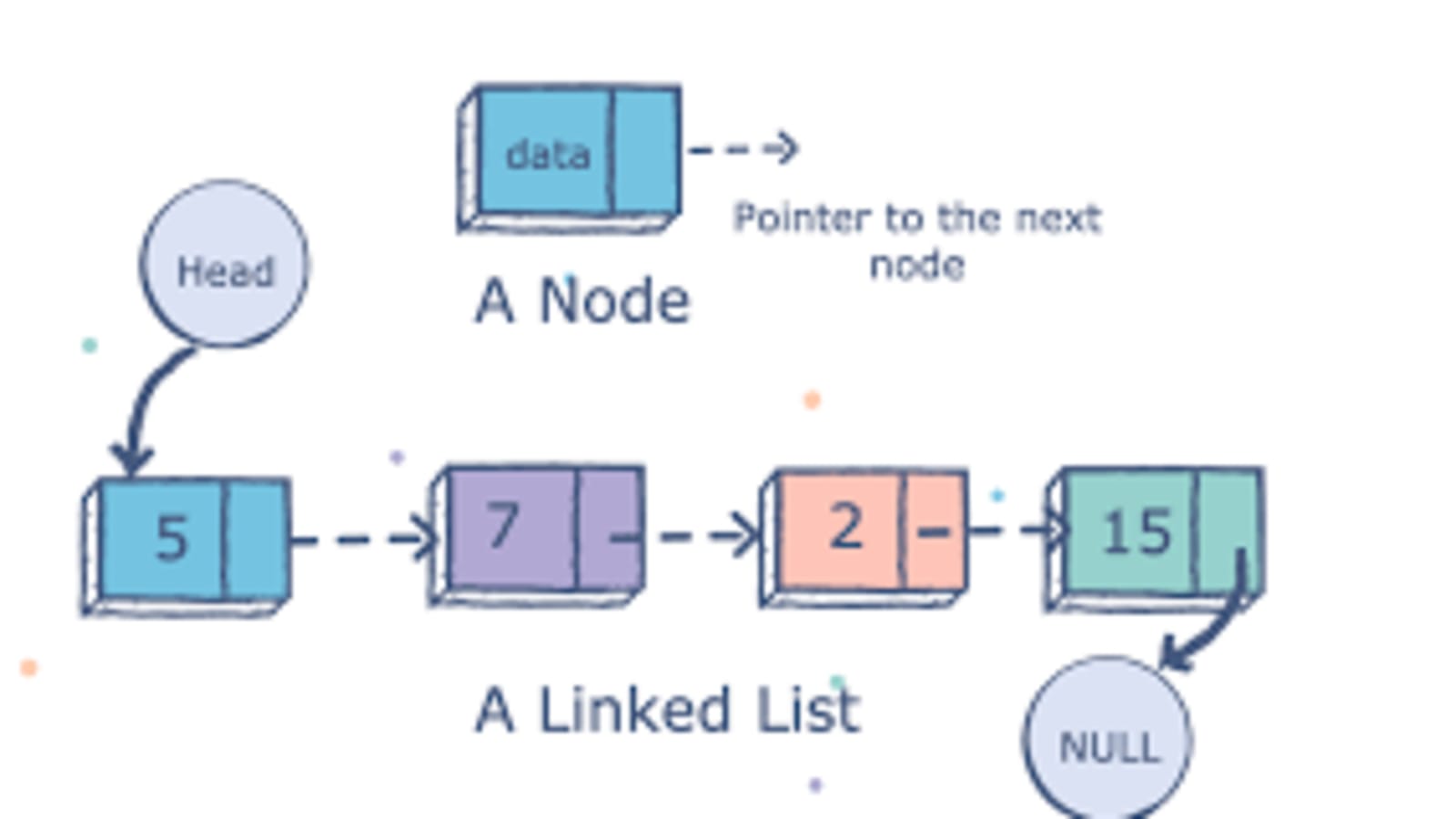
A linked list can be small or huge, but no matter the size, the parts that make it up are actually fairly simple. A linked list is made up of a series of nodes, which are the elements of the list.
The starting point of the list is a reference to the first node, which is referred to as the head. Nearly all linked lists must have a head, because this is effectively the only entry point to the list and all of its elements, and without it, you wouldn’t know where to start! The end of the list isn’t a node, but rather a node that points to null, or an empty value. A single node is also pretty simple. It has just two parts: data, or the information that the node contains, and a reference to the next node.
If we can wrap our heads around this, then we’re halfway there. The way that nodes work is super important, and super powerful, and could be summarized as this:
A node only knows about what data it contains, and who its neighbor is.
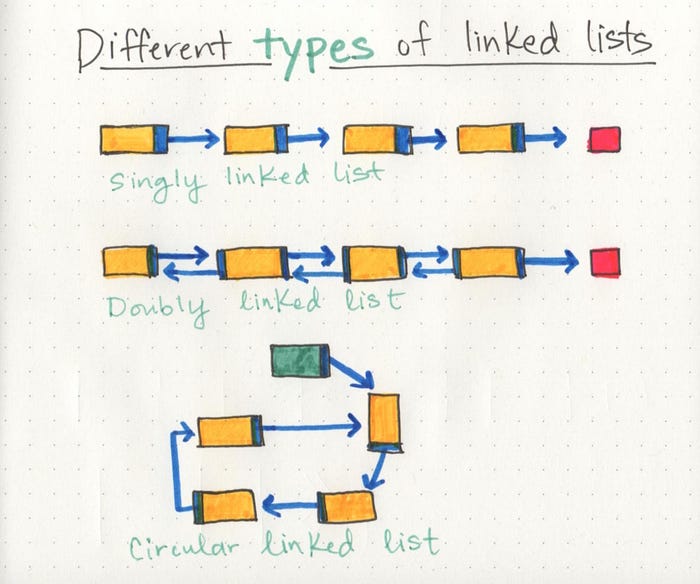
But just as a node can reference its subsequent neighbor node, it can also have a reference pointer to its preceding node, too! This is what we call a doubly linked list, because there are two references contained within each node: a reference to the next node, as well as the previous node. This can be helpful if we wanted to be able to traverse our data structure not just in a single track or direction, but also backwards, too.
A circular linked list is a little odd in that it doesn’t end with a node pointing to a null value. Instead, it has a node that acts as the tail of the list (rather than the conventional head node), and the node after the tail node is the beginning of the list. This organization structure makes it really easy to add something to the end of the list, because you can begin traversing it at the tail node, as the first element and last element point to one another. Circular linked lists can start to get really crazy because we can turn both a singly linked list and a doubly linked list into a circular linked list!
Linked lists are super simple, but they seem to have this reputation of being fairly complicated. Their reputation, as they say, precedes them.